JoinAnswers
The JoinAnswers node takes Answers from two or more Reader or Generator nodes and joins them to produce a single list of answers.
| Position in a Pipeline | Joins the output of two or more Nodes that return Answers |
| Input | Answers |
| Output | Answers |
| Classes | JoinAnswers |
Usage
To initialize the Node, run:
Copied!
from haystack.nodes import JoinAnswers
join_answers = JoinAnswers( join_mode="concatenate", sort_by_score=True)
There are two available join_modes:
concatenate: Combines documents from multiple readersmerge: Aggregates scores of individual answers. If you use this option, you can also specify theweightsparameter which assigns importance to the input nodes. By default, all nodes are assigned equal weight.
Optionally, you can use the top_k parameter to specify the number of answers to be displayed.
Note: Answers coming from a Generator have no score.
You will need to set sort_by_score=False to join these with Answers coming from other sources.
To use the Node in a pipeline, run:
Copied!
from haystack.pipelines import Pipelinefrom haystack.nodes import JoinAnswers, TableTextRetriever, RouteDocuments, TextReader, TableReader
join_answers = JoinAnswers( join_mode="concatenate", top_k_join=10)
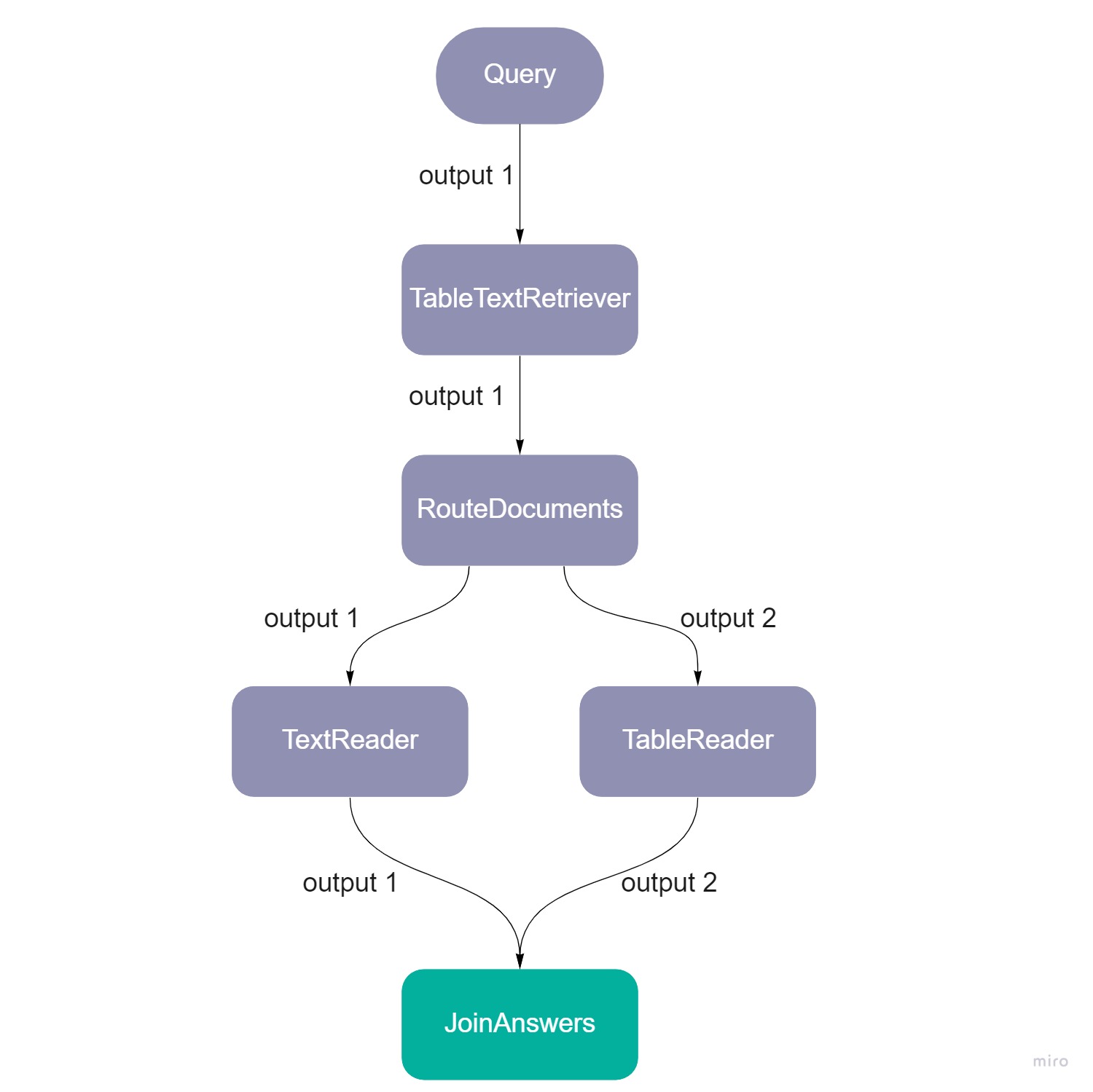
pipeline = Pipeline()pipeline.add_node(component=table_retriever, name="TableTextRetriever", inputs=["Query"])pipeline.add_node(component=route_docs, name="RouteDocuments", inputs=["TableTextRetriever"])pipeline.add_node(component=text_reader, name="TextReader", inputs=["RouteDocuments.output_1"])pipeline.add_node(component=table_reader, name="TableReader", inputs=["RouteDocuments.output_2"])pipeline.add_node(component=join_answers, name="JoinAnswers", inputs=["TextReader", "TableReader"])res = pipe.run(query="What did Einstein work on?")
Use Case
A typical use case for JoinAnswers is as follows:
- Your documents contain different types of data, for example tables and text.
- You use the
RouteDocumentsnode to split your documents by content type. - You use a different reader for each document type and you get predicted answers form each reader separately.
- You use the
JoinAnswersnode to join the answers in a single list.
Here's what an example pipeline with the JoinAnswers node could look like: